Asistente de IA híbrido: evolución de los agentes actuales
Escribí este artículo yo mismo y luego pedí a la IA que mejorara mi inglés.
Esta es mi opinión personal como arquitecto de soluciones, construyendo software en la nube y plataformas de datos durante 20 años. Es más bien una reflexión sobre cómo veo Actor dentro de 1-2 años.
A medida que los asistentes de IA se vuelven más capaces, la arquitectura subyacente se vuelve tan importante como los propios modelos. Actualmente la evaluación de agentes se basa en los modelos usados, el marco y los prompts.
Para sistemas como Actor, diseñados para operar en correos electrónicos, calendarios, documentos y flujos de trabajo empresariales, un enfoque puramente basado en la nube o puramente local alcanza rápidamente sus límites.
Lo que empieza a surgir en su lugar es una arquitectura híbrida, donde la inteligencia y la ejecución se distribuyen entre dispositivos locales, infraestructura privada y modelos en la nube.
Esto tiene menos que ver con una preferencia tecnológica y más con una necesidad arquitectónica.
Los límites de un asistente puramente en la nube
La mayoría de los asistentes de IA actuales operan principalmente en la nube. Esto tiene sentido al principio: los modelos son grandes, la infraestructura está centralizada y las actualizaciones son sencillas. Además, la inferencia es barata (o al menos para algunos modelos).
Pero una vez que un asistente se integra profundamente con los sistemas de trabajo, surgen algunos problemas estructurales.
Primero, Los límites de los datos importan.
Los asistentes de trabajo interactúan con información altamente sensible: documentos financieros, correos internos, contratos, hojas de ruta de producto, conversaciones de RR. HH. Muchas organizaciones no pueden legal ni operativamente transmitir estos datos continuamente a infraestructura externa.
Entonces La conectividad se convierte en una dependencia.
Un asistente de trabajo que deja de funcionar en un avión, en un túnel de tren o durante problemas de red se vuelve poco fiable para las operaciones diarias.
La IA en la nube es poderosa, pero no puede manejar de forma realista todas las capas del sistema.
Los límites de un asistente puramente local
En el extremo opuesto, ejecutar todo localmente también encuentra limitaciones importantes.
Los modelos de razonamiento más capaces aún requieren Infraestructura de cómputo significativaAunque el hardware local está mejorando rápidamente —Apple Silicon, NPU y chips dedicados de IA—, ejecutar modelos de vanguardia para razonamiento complejo o síntesis de múltiples documentos sigue siendo impráctico en la mayoría de los dispositivos.
En segundo lugar, La latencia se acumula en flujos de trabajo de agentes.
Un asistente que realiza múltiples pasos como leer un correo, extraer tareas, revisar el calendario, redactar una respuesta y programar seguimientos crea una cadena de llamadas a modelos e interacciones con APIs. Incluso pequeños retrasos se acumulan cuando las acciones son secuenciales.
También existe un reto de gobernanza.
Gestionar modelos en miles de dispositivos de empleados introduce complejidad operativa: actualizaciones, parches de seguridad, gestión de configuraciones y monitorización del cumplimiento.
Por último, muchos flujos de trabajo de asistentes requieren estado compartido.
Una cronología de proyecto, una base de conocimientos del equipo o un sistema de tareas colaborativo no pueden residir completamente en el equipo de una sola persona.
La inteligencia local por sí sola tampoco puede ofrecer la imagen completa.
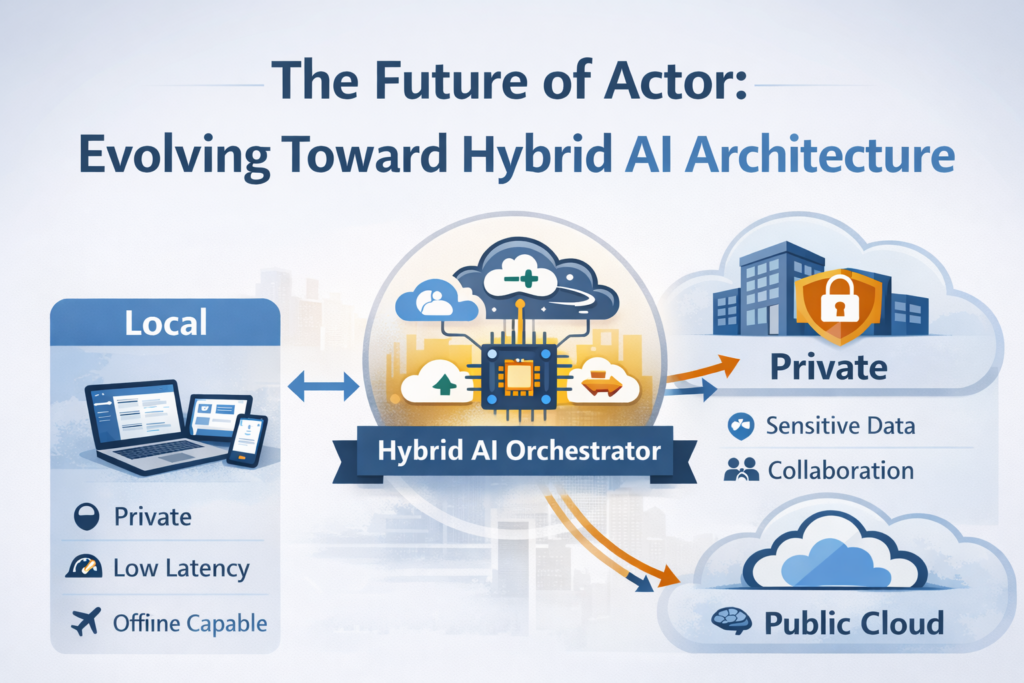
Una dirección probable: inteligencia distribuida
Una arquitectura más natural para asistentes como Actor es un modelo de inteligencia distribuida, donde distintas capas del sistema se ejecutan en diferentes entornos.
Un desglose simplificado podría verse así:
Capa local (entorno de ejecución del dispositivo)
Responsable de la conciencia del entorno del usuario y de acciones rápidas.
Responsabilidades típicas:
- acceder a archivos, aplicaciones y notificaciones locales
- detectar señales contextuales (documentos activos, reuniones, correos electrónicos)
- ejecución de acciones rápidas y privadas
- almacenamiento en caché de conocimientos usados con frecuencia
Infraestructura privada (nube de la organización o del usuario)
Responsable del estado compartido y del procesamiento de datos sensibles.
Responsabilidades típicas:
- bases de conocimiento de la empresa
- memoria compartida del agente
- contexto de colaboración del equipo
- procesamiento de documentos sensibles
Modelos de nube pública
Responsable del razonamiento intensivo y del conocimiento a gran escala.
Responsabilidades típicas:
- tareas de razonamiento profundo
- síntesis compleja entre múltiples documentos
- recuperación extensa de conocimiento
- capacidades lingüísticas avanzadas
En este modelo, el el runtime local actúa como el orquestador, decidiendo dónde debe ejecutarse cada tarea.
La importancia del límite de confianza
Una de las decisiones de diseño más importantes se convierte en definir el límite de confianza.
En términos prácticos, esto significa responder preguntas como:
- ¿Qué datos nunca abandonan el dispositivo?
- ¿Qué datos pueden trasladarse a infraestructura privada?
- ¿Qué tareas pueden usar modelos externos de forma segura?
- ¿Cómo se registran y auditan estas decisiones?
Este límite se vuelve crítico para la adopción empresarial.
Las organizaciones no solo quieren capacidades de IA — también quieren previsibilidad y control sobre hacia dónde fluye la información.
Por qué esta arquitectura probablemente se convertirá en estándar
Varias tendencias de la industria apuntan en esta dirección.
La aceleración por hardware está mejorando rápidamente en dispositivos locales, lo que permite modelos ligeros e inferencia local rápida.
Al mismo tiempo, las capacidades de modelos de vanguardia siguen escalando en entornos en la nube, manteniendo una brecha que hace atractivo el procesamiento en la nube para tareas complejas.
Las empresas requieren cada vez más garantías de gobernanza de datos, empujando a los sistemas de IA hacia arquitecturas que puedan respetar los límites internos.
Por último, los marcos emergentes de agentes ya están construidos alrededor de enrutamiento multimodelo, donde distintos modelos y entornos de ejecución manejan diferentes tareas.
Las arquitecturas híbridas se alinean naturalmente con este patrón.
Qué significa esto para Actor
Para Actor específicamente, una arquitectura híbrida podría desbloquear varias capacidades:
Un entorno de ejecución local podría comprender de manera continua el entorno del usuario, el contexto del correo electrónico, las reuniones y los documentos sin necesidad de transmitirlo todo externamente.
Una capa de infraestructura privada de Actor podría mantener la memoria del usuario, los grafos de tareas y el contexto colaborativo.
Entonces se podrían invocar modelos en la nube de forma selectiva para tareas que realmente requieran razonamiento más profundo.
En lugar de un único punto final de IA, Actor se convierte en un sistema que coordina la inteligencia a través de capas.
Esta arquitectura también permite a los usuarios y a las organizaciones elegir diferentes estrategias de despliegue según sus necesidades:
- nube personal
- infraestructura de la empresa
- híbrido local y en la nube
- despliegues completamente privados
En otras palabras, Actor evoluciona de ser solo un asistente a convertirse en una capa cognitiva distribuida para el trabajo.
Mirando hacia el futuro
El futuro de los asistentes de trabajo probablemente no estará definido por un único modelo o proveedor.
En cambio, estará moldeado por cómo se orquesta la inteligencia a través de los entornos.
Los sistemas que puedan combinar privacidad, capacidad de respuesta y razonamiento potente tendrán una ventaja estructural.
Las arquitecturas híbridas parecen ser una de las vías más prometedoras para lograr ese equilibrio.
PD: Estoy reconstruyendo toda la arquitectura para estar listo para un modelo híbrido en un futuro cercano. Es mucho trabajo, llevará tiempo; sin embargo, es mi pasión.